Application builder tutorial
Learn your way around Baseten by building an ML-powered application.
The best way to learn is by doing. In this twenty-minute tutorial, you'll visit every major piece of Baseten (and most of the minor ones too) while building an ML-powered application. Then, you'll know everything you need to build your own projects!
In this tutorial, we'll build an application that uses a pre-trained extractive question answering model to answer user-provided questions based on the appropriate Wikipedia article. The user will enter the link to a Wikipedia article and a question about its contents, and the application will attempt to answer the question, plus store the question, answer, and confidence in a database for later review.
We're going to build this application in six steps. Follow along from your Baseten account!
Step 1: Deploy the model
Extractive question answering takes a text and a question and attempts to extract an answer from the text. You've likely seen this type of interaction before from Google search results. When you search, for example, "How old is Google," it retrieves a specific answer from the top search result, saving you the time of clicking on and reading the linked source.
With Baseten, you can deploy a pre-trained model to do the same thing in under a minute:
Go to the models page of your baseten account
Click on "Explore models"
On the explore models page, search for and select "Extractive question answering"
Click on the extractive question answering model
Click the "Deploy model" button and a modal will appear
Toggle off "Create a starter application" as we are going to build our own
Click the "Deploy model" button in the modal
The model should be active and ready for use within seconds!
While it is not necessary for this tutorial, you can test the model right away. Create an API key then enter the following curl command in your terminal:
Where:
YOUR_MODEL_ID is an alphanumeric sequence like
5qls3np, found on your model dashboardYOUR_API_KEY is the value of your API key
MODEL_INPUT is a string
[{"question": "Question here", "context": "At least a paragraph of text here"}]
Running this command will get you the model's prediction.
Step 2: Create an application
Now that the model is deployed, go to the applications page and click on the green "Create an application" button .
This will open your new app in the application builder. You can rename your application by clicking on the name in the upper-left side of the header (Applications > "Untitled application"). Type in something like "Wikipedia answerer" and the application name will be saved automatically.
From here, you can reverse the order of step 3 (build the frontend) and step 4 (build the backend). How you build your applications is up to you. The frontend is presented first in this tutorial to help you visualize the purpose of the back-end code, but many developers find success working in the opposite direction.
Step 3: Build the frontend
Baseten's drag-and-drop view builder means you can build a frontend without learning HTML, CSS, or React. And if you do already know them, you'll appreciate how much time you save not writing boilerplate code. To add a component to your view, just drag it onto the canvas, put it in the desired position, and adjust its size. Then, you can configure its properties.
First, rename the view by clicking on the three-dot menu next to "View1" on the left-side navbar. Call it whatever you want, like "Main view."
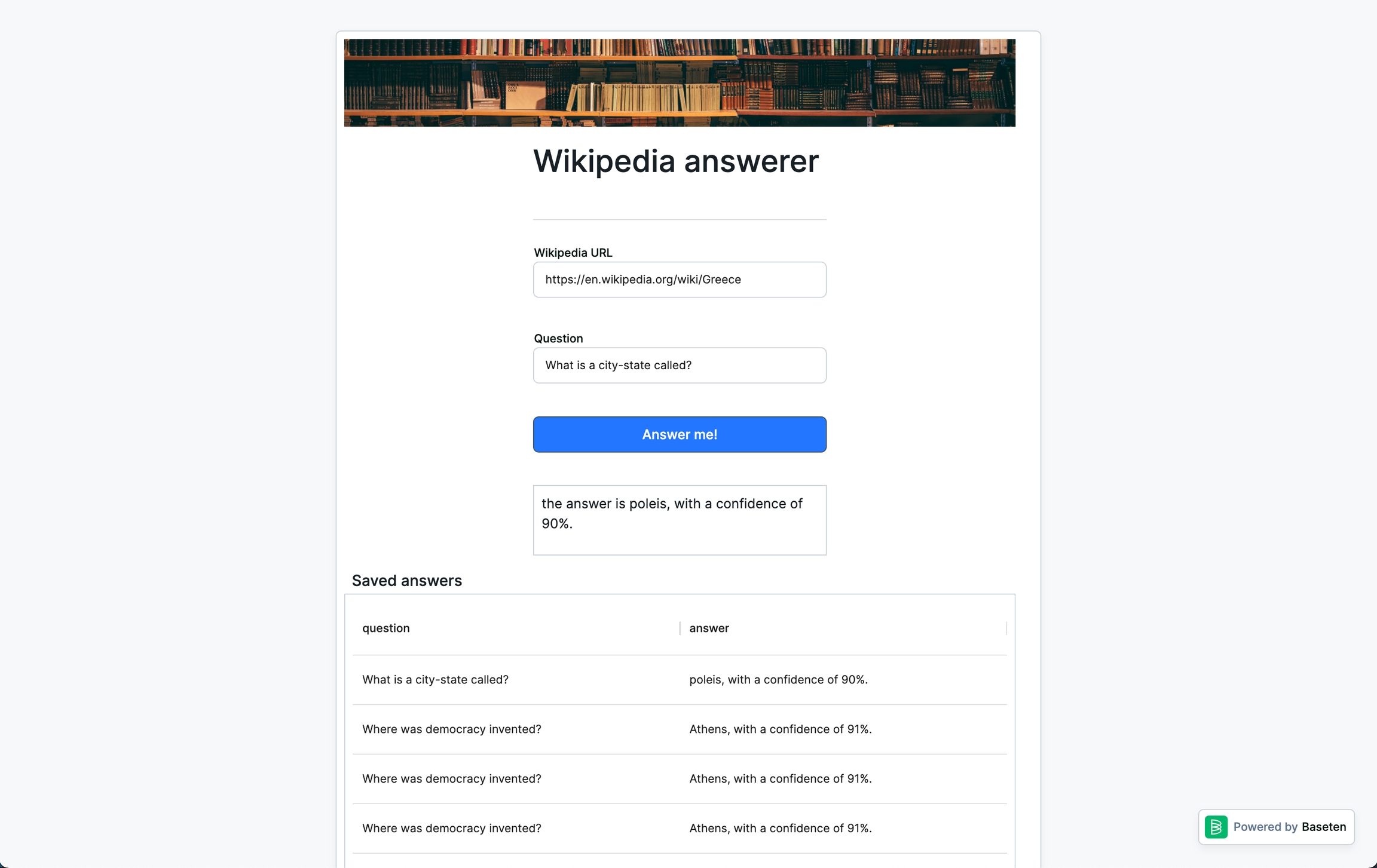
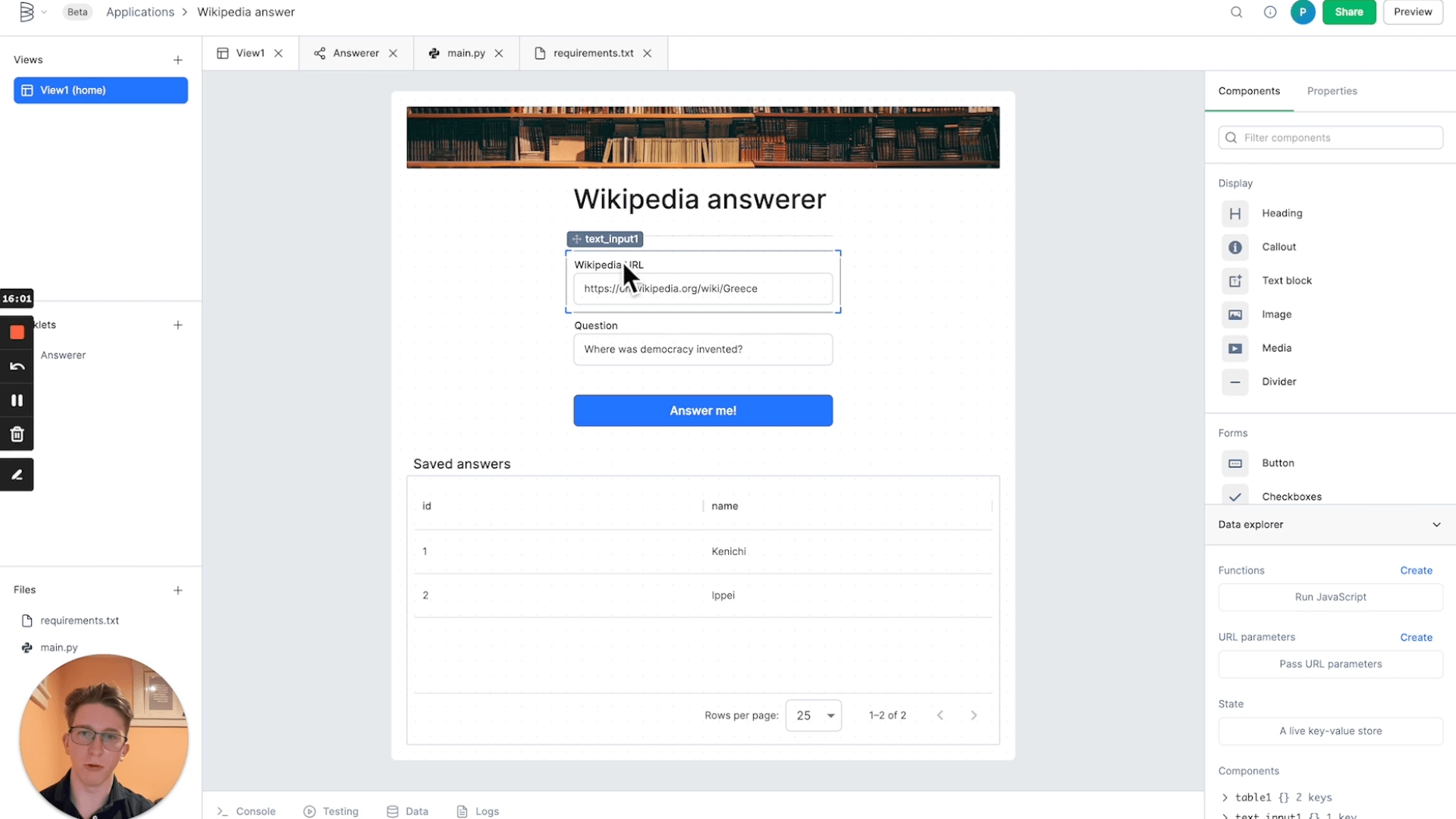
The full UI only requires 8 components. First, click on the canvas itself to open up its properties. Set the canvas width to small; we'll be using a single-column layout for this application. Then, drag in and configure each component to build the UI shown below.
For each component, set its properties as described by the nested bullet points:
Image
URI: https://images.unsplash.com/photo-1507842217343-583bb7270b66
Heading
Heading text: Wikipedia answerer
Heading level: h1
Divider
No configuration needed, just resize it
Text input
Input label: Wikipedia URL
Placeholder text: https://en.wikipedia.org/wiki/Topic
Initial value: https://en.wikipedia.org/wiki/Greece
Text input
Input label: Question
Placeholder text: Enter a question here
Initial value:value Where was democracy invented?
Button
Label: Answer me
Intent color Up to you!
Event handlers We will add these in step 5
Text block
Show border: Toggle on
Body: Delete the existing text for now, we'll add something in step 5
Table
Show header: Toggle on
Header text: Saved answers
Show border: Toggle on
Paginate rows: Toggle on
Data: We'll configure the data in step 5
With these components in place, you can imagine how the user will interact with the application. Now, it's time to build the backend to support those interactions.
Step 4: Build the backend
The backend of any application built on Baseten is one or more worklets. A worklet is a serverless function that you can call via an API endpoint. This application only requires a single worklet, which we will build in this step, along with a data table to store saved answers and a query to retrieve them.
We'll rename the worklet just like we did with the view. Click the three-dot menu next to "Worklet1" and select rename, and call it something like "Answerer."
Our worklet will have four blocks: a code block, a model block, and two more code blocks. But, to have code to add to the code blocks, we'll need to edit main.py in the Files menu to include custom code.
Add the following function to main.py:
This function relies on the wikipedia package, a third-party package installable via pip. You can install this package by including it in your requirements.txt file, then clicking "Save & install" in the right-hand corner. Package installation might take a few seconds longer than on your local machine as various systems need to be restarted, so wait a moment after installation before trying to run the code.
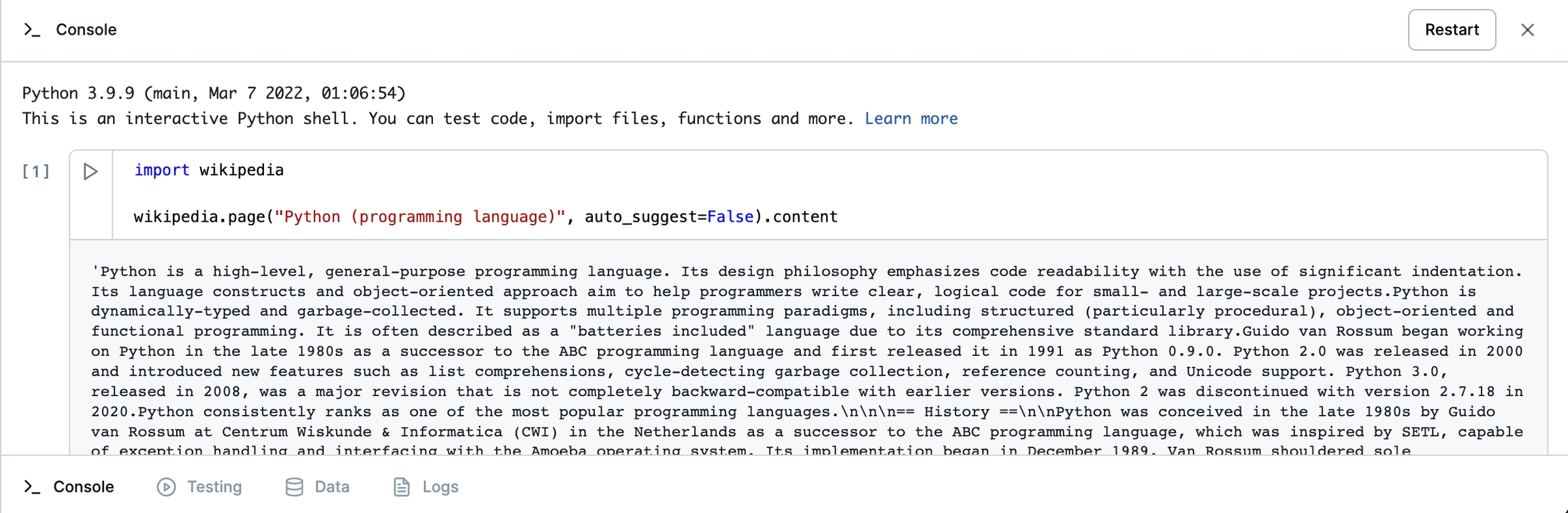
You can test this code in the console, which expands from the bottom tab menu. Once your Python environment loads, treat the interactive Python shell just like a Jupyter notebook. When you run the last cell in your console, it'll create a new one, and you can restart your session to clear output or to bring in installed packages.
In your console, try running the code below to make sure wikipedia is installed properly.
You should receive the full text of the Wikipedia page on the Python programming language as a return value.
Now, return to your worklet and add a code block. Set main.py as the file and get_page as the function.
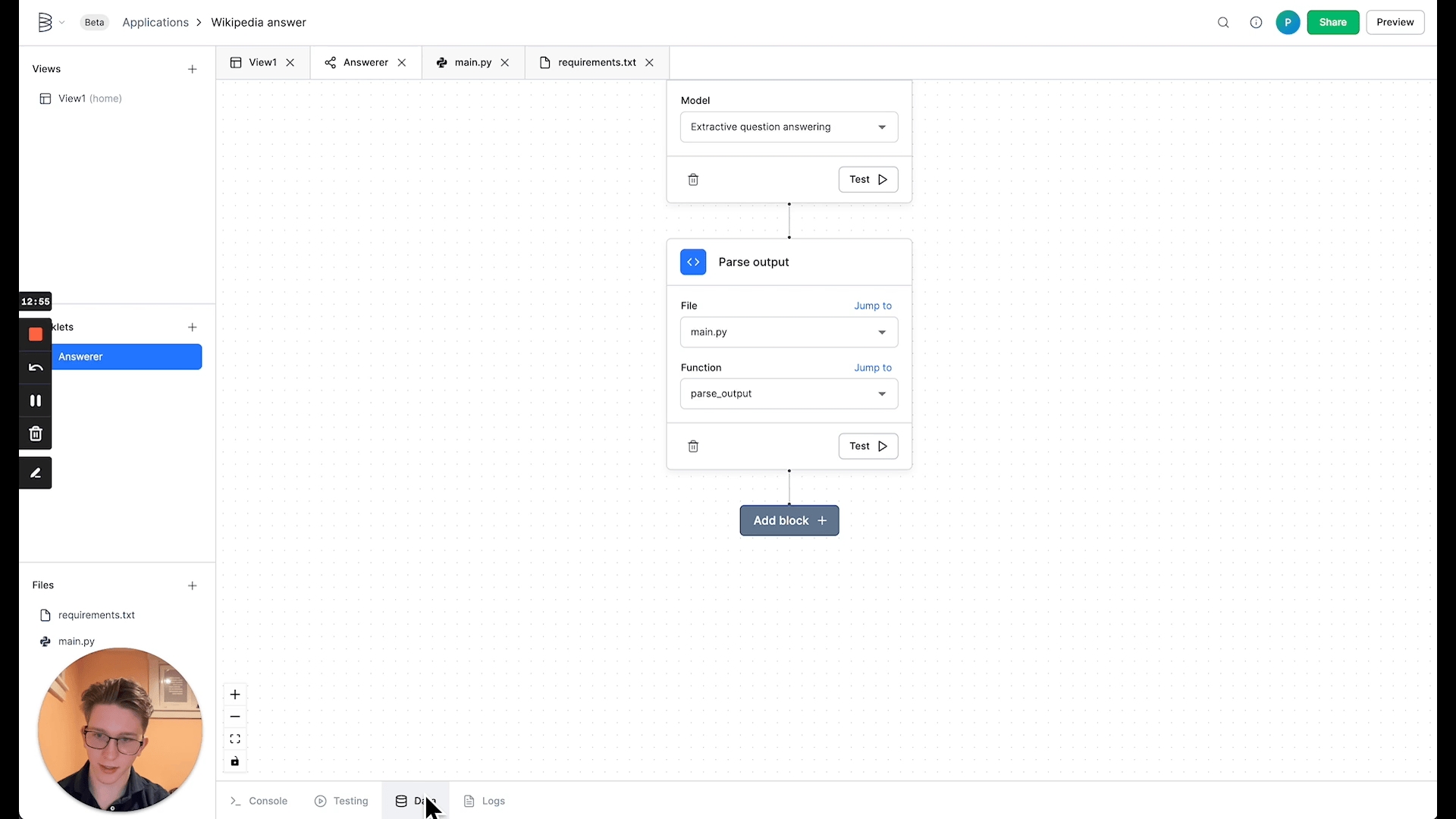
Next, we'll add a model block to the worklet. Add the block and set the model to Extractive question answering.
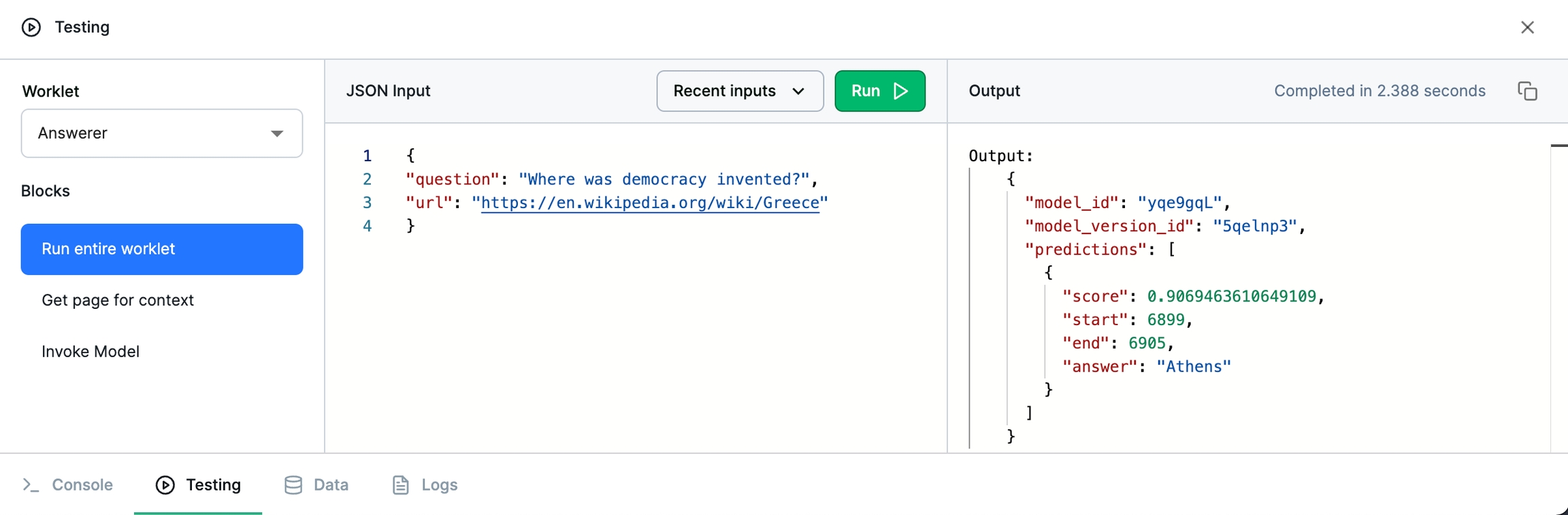
While the console was useful for testing individual bits of code, the testing tab next to it is built for testing your worklets. Open the testing tab and run your worklet on this input:
The testing tab will show you the model's output, and you can always click over to the logs tab to see logs of the worklet run in case of error.
This setup gives you your answer, but it could be formatted in a more human-readable manner. So, return to the main.py file and add this function:
And, back in the worklet, you know what to do: create a code block and set its file to main.py and its function to parse_output.
Now, the worklet is almost ready to go, but we also want to store the results of every run to show in the table.
Create a data table by going to the data tab, clicking "New" then selecting "New table." This will take you to another page, where you'll want to name your new table StoredAnswers so the code below works properly. Set the fields as follows:
question:stringanswer:string
Then, save the table with the button on the lower-right corner. Once the table is saved, you can close that page and return to the application builder.
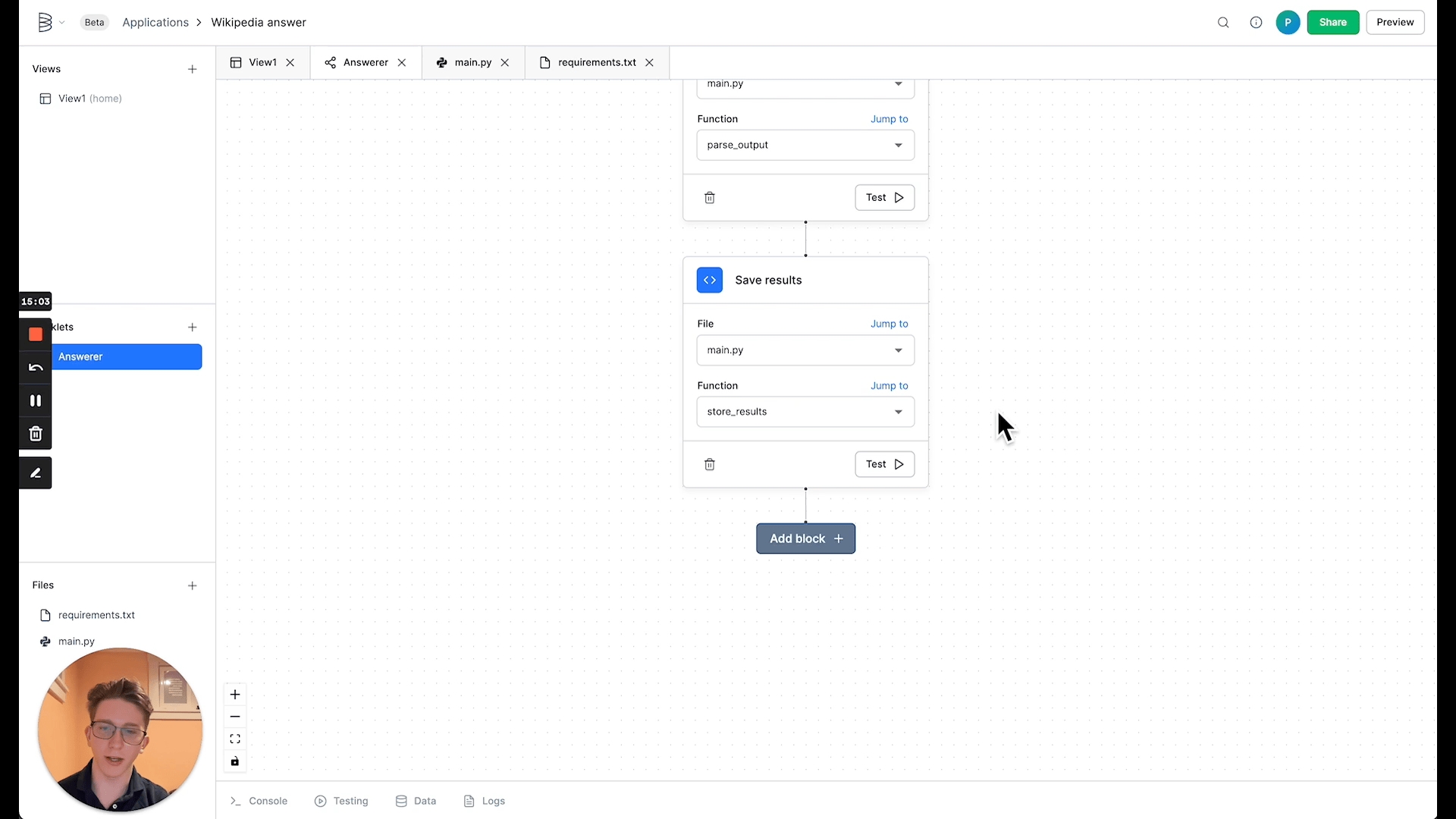
With the table created, we can write to it from a third code block. Add the following function to main.py:
And returning to your worklet, append a code block with the file main.py and function store_results.
Finally, we know how to put data into the table, but how do we get it back out? We'll write and save a query to access the data.
From the data tab, click "New" then select "New query." This will open the query builder modal. Give your query a name like "Get answers" then paste in the following SQL:
You can run the query to ensure there are no syntax errors, but it won't return any data yet. Save the query and return to your view to finish the application.
Step 5: Wire everything up
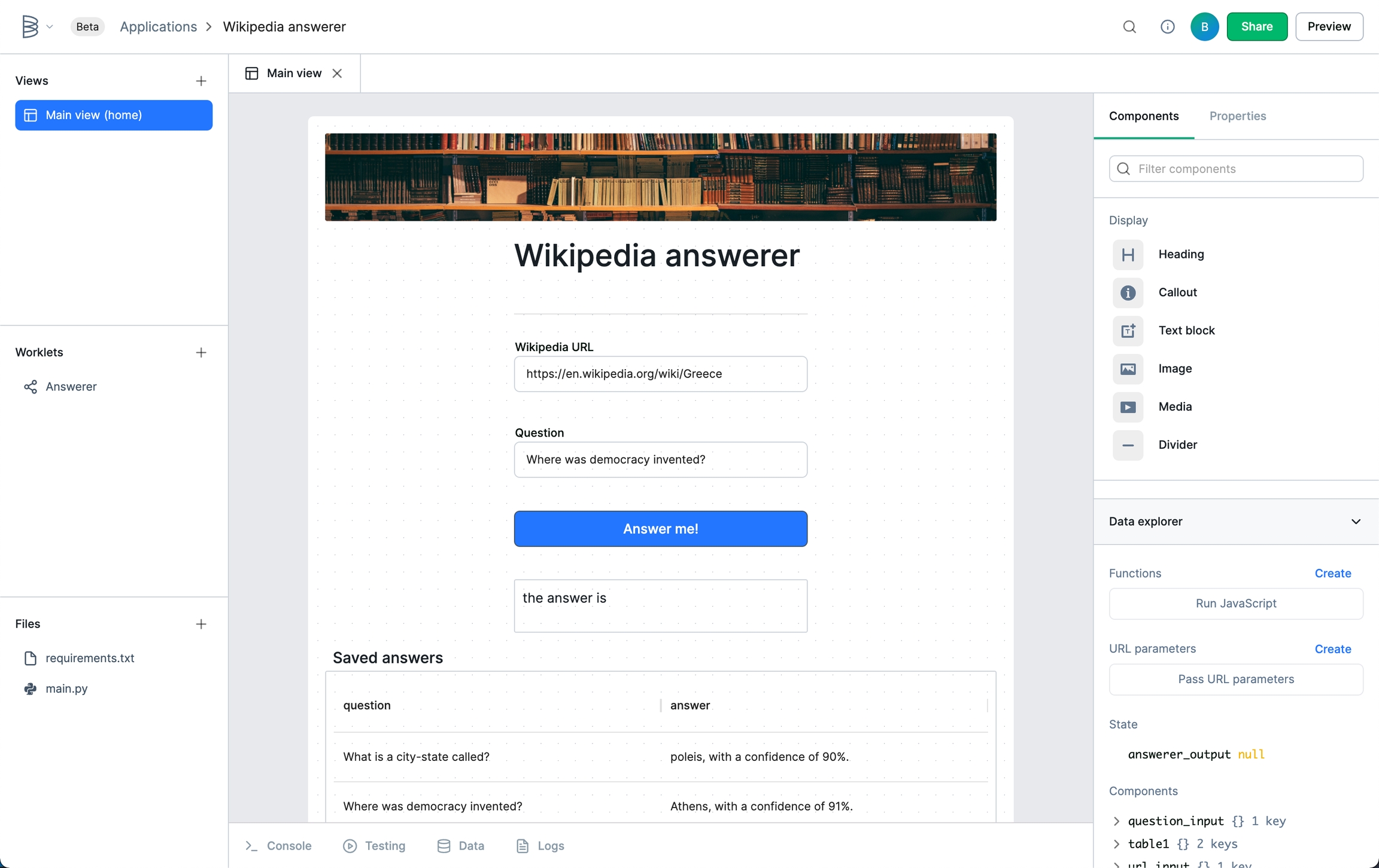
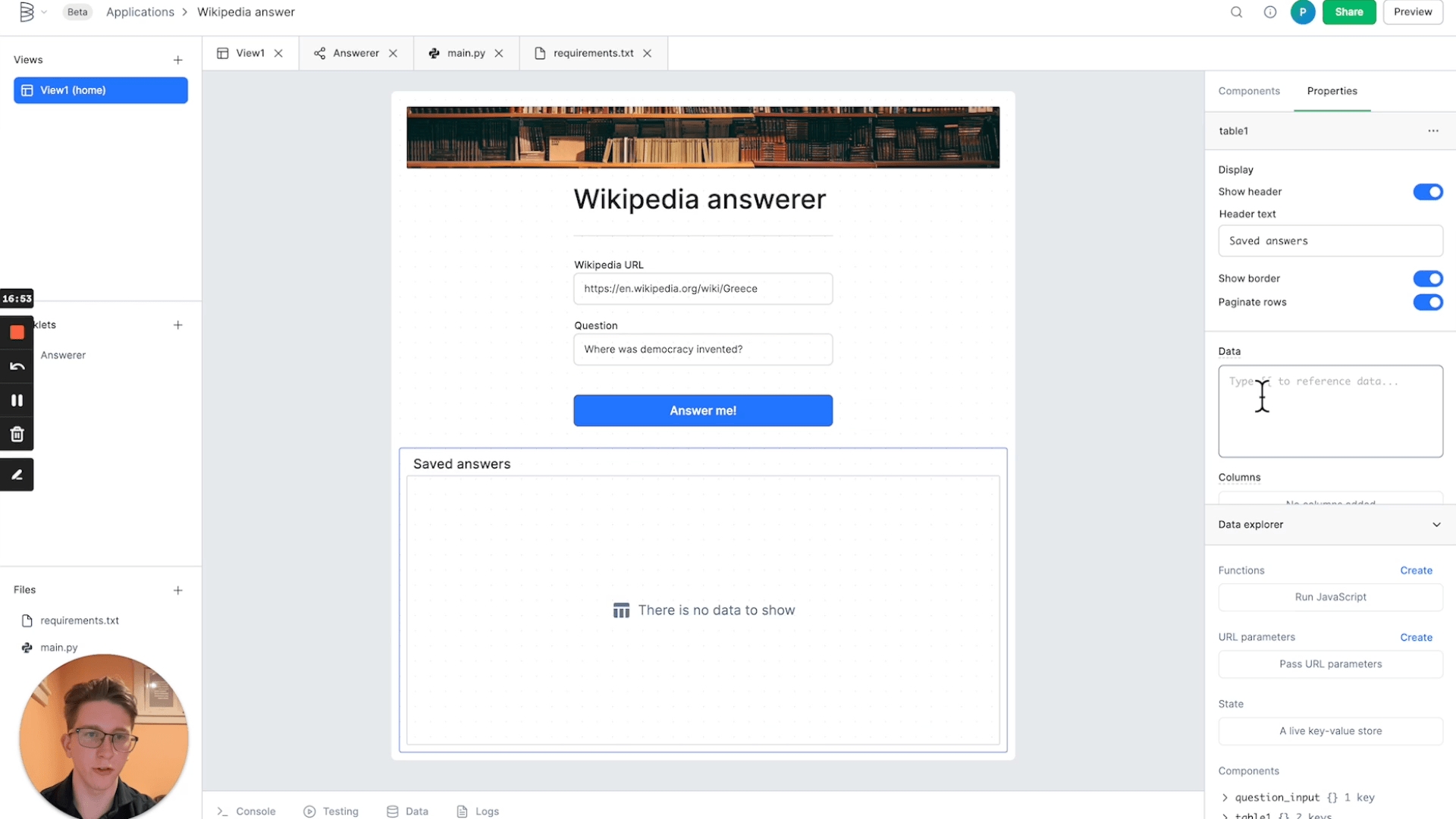
Before we get started connecting the frontend and backend, a little step that will make things cleaner is renaming some of our components. When you click on a component like the Wikipedia URL field, you'll see its name is something like "text_input1" in the properties menu. Clicking on that name will let you rename the component. Give your two text input components more meaningful names so that you can reference them later, like "url_input" and "question_input."
Then, click on your table and clear out any existing text in the "Data" field. Type in two curly braces ({{) to open the binding menu. Bindings connect data across your view's components, worklets, and data queries. From the menu, select the query you just built, and don't forget to use }} to close the binding. The table won't show any data yet, but we'll give it some shortly.
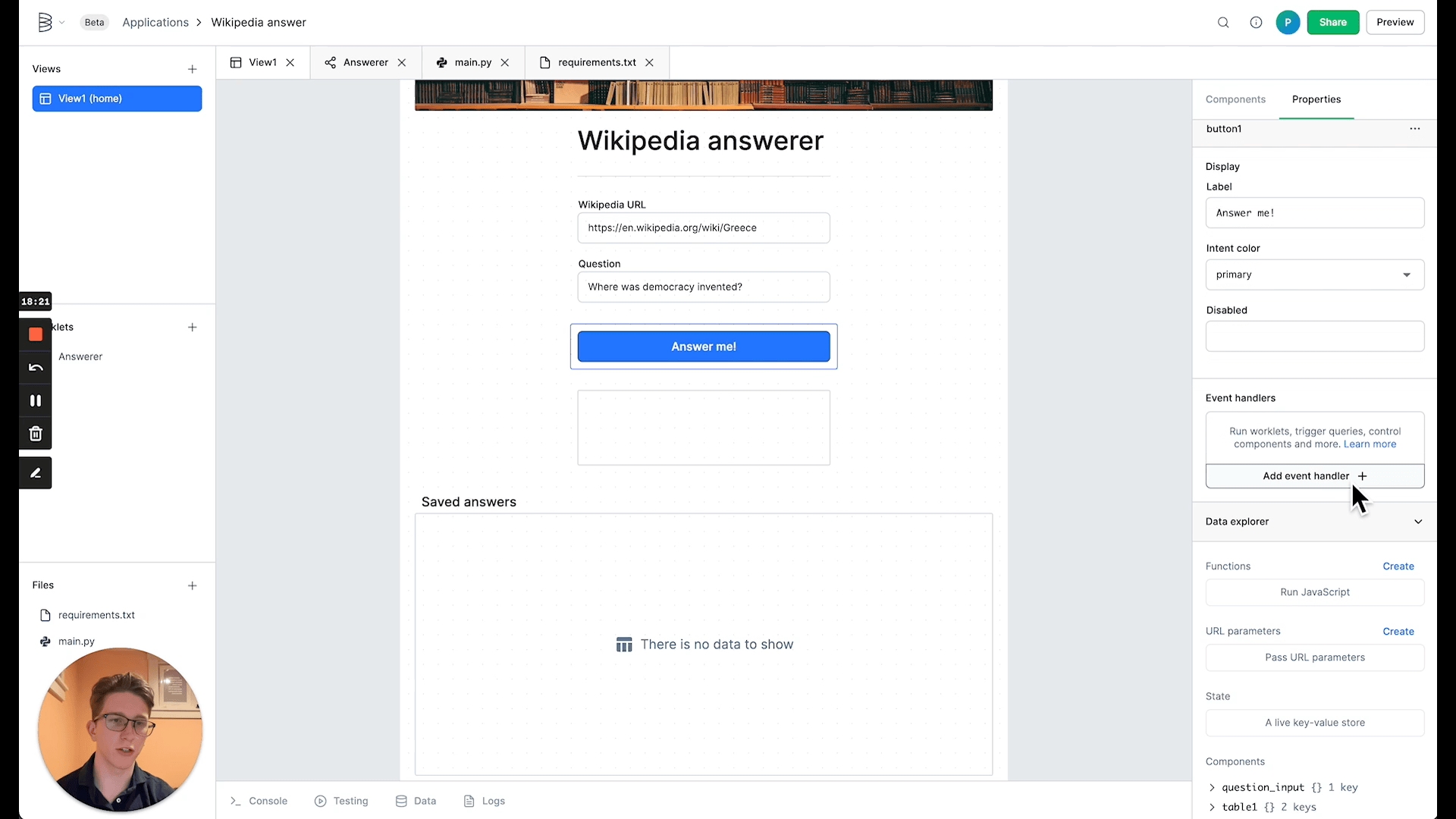
Now comes the big move that ties the whole application together: triggering the worklet. Click on the button in your view to access its property menu, then scroll down to event handlers. Click "Add event handler" and set the action to "Run worklet."
Select the worklet you built in step 4, and give it the following parameters. Do not copy and paste in binding tags, instead, type in the double curly braces and select the desired binding from the drop-down menu.
url: binding to{{url_input}}question: binding to{{question_input}}
The output will be saved to the state field answerer_output assuming your worklet is also called "answerer." You can see this value under state in the data explorer in the bottom-right corner of the screen.
Then, add a second event handler and set its action to "Refresh data sources." Event handlers are run sequentially, so this one won't fire until the worklet invocation has completely finished. The "Refresh data sources" action will refresh all bindings in your application, such as the data in the table and the value of the text area that we are about to set.
Lastly, set the value of the text field to the answer is {{answerer_output}} (remember, don't copy and paste binding tags) and you're all set.
Try it out! You can interact with your application directly from the view builder.
Step 6: Publish your app!
Your app is ready to go! While we have been testing everything in the application builder itself, your end users will need a cleaner interface. There are two ways to share the app.
To keep the application private, you can click "Preview" to see how the app will look to end users. You can share a link to this preview with anyone in your Baseten workspace. If you want to invite someone to use the application without being able to edit it, you can create an operator account for them within your Baseten workspace.
To make the application publicly available to anyone on the internet with a link, click "Share." Toggle the "Make public" switch, then copy the link to the operator view and send it to anyone or share it on social media. While anyone with a link will be able to use your application, they will not be able to edit it or see anything else in your Baseten account.
Step 7 (optional): Expand your knowledge
The app is totally built and ready to go. However, if you want to try navigating the Baseten platform on your own, here are some ideas for expanding the capabilities of the application you just built.
If you get stuck, watch the associated video solution to get unblocked!
Toggle full text
Right now, the model is only fed the first 10,000 characters of a given Wikipedia page. The model can analyze a full page, it just takes longer. Use a Select component to let the user choose between a fast answer or using the complete text. Pass the value of the component into the Worklet call as an additional parameter, and in the code for the first block only truncate the source text if the user wants a fast answer.
Avoid wrong answers
Like all models, the extractive question answering model has its limits. Most importantly, if the question asked has nothing to do with the provided text, you'll receive a nonsensical answer. Add a check when parsing results that tests if the confidence in the answer is at least 50%. If not, instead return "I don't know." Try using a decision block to make the check.
Custom data source
Wikipedia is a great source of knowledge, but what if you want to adapt this application to work with your own data source, like your company's documentation? This implementation is substantially more involved than the previous two, as you'll have to implement a custom web scraper or load the information from a data connection like text files stored in AWS S3.
As there is no one right answer here, there isn't a video solution, but if you need help developing a custom ML-powered application based on extractive question answering or any other ML model, email support@baseten.co or use the Intercom button in the lower-right corner of these docs to get in touch with us!
You did it!
You just learned how to deploy a model, create an application, build a view and worklet then connect them with bindings, use a Baseten Postgres table, and write custom code. With an understanding of these core aspects of the Baseten platform, you're now ready to build and ship ML-powered applications that deliver real business value.
Last updated